
 ▶
▶
AI & Machine Learning
TensorFlow Developer Professional Certificate
Get started now: https://learn.deeplearning.ai/specializations/tensorflow-developer-professional-certificate The TensorF…





![Living human brain cells play DOOM on a CL1 [video]](https://img.youtube.com/vi/yRV8fSw6HaE/hqdefault.jpg)








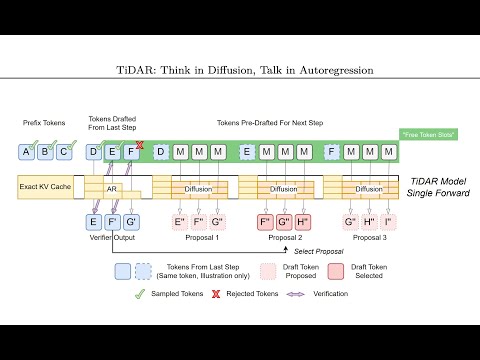

![[Paper Analysis] The Free Transformer (and some Variational Autoencoder stuff)](https://img.youtube.com/vi/Nao16-6l6dQ/hqdefault.jpg)
![[Video Response] What Cloudflare's code mode misses about MCP and tool calling](https://img.youtube.com/vi/0bpYCxv2qhw/hqdefault.jpg)
![[Paper Analysis] On the Theoretical Limitations of Embedding-Based Retrieval (Warning: Rant)](https://img.youtube.com/vi/zKohTkN0Fyk/hqdefault.jpg)



![[GRPO Explained] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://img.youtube.com/vi/bAWV_yrqx4w/hqdefault.jpg)
